
 AMD introduced its most powerful artificial intelligence accelerator, MI300X. The new accelerator promises up to 60% better performance than Nvidia H100.
AMD introduced its most powerful artificial intelligence accelerator, MI300X. The new accelerator promises up to 60% better performance than Nvidia H100.AMD Instinct MI300X is built with TSMC’s advanced packaging technology and chiplet design. Let’s look at how the accelerator, which has quite impressive figures, compares with Nvidia H100.
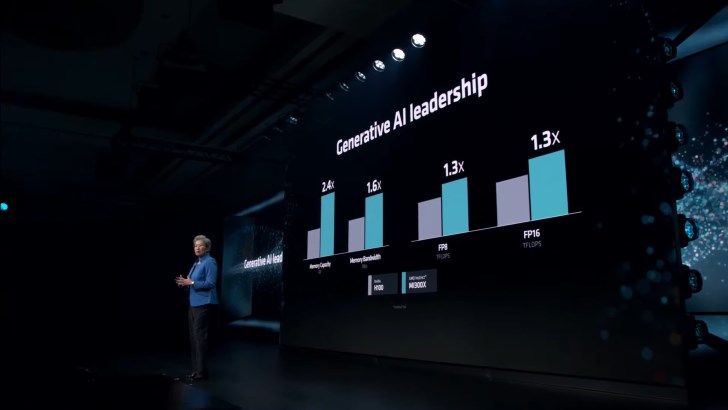
- 2.4 times higher memory capacity
- 1.6x more memory bandwidth
- 1.3x more FP8 TFLOPS
- 1.3 times more FP16 TFLOPS
- Llama 2 70B is up to 20% faster in head-to-head comparison
- FlashAttention 2 is up to 20% faster in head-to-head comparison
- Llama 2 70B is up to 40% faster on 8v8 server
- FlashAttention 2 is up to 60% faster on 8v8 server
Up to 60% faster than Nvidia H100
Overall, the MI300X outperforms the H100 by up to 20% in large language model (LLM) core TFLOPs. On the platform scale, when 8 MI300Xs are compared with 8 H100s, the difference becomes even wider, with Llama 2 70B performing 40% better and Bloom 176B performing up to 60% better.
 AMD says the MI300X is on par with the H100 in AI training performance, is competitive in price-performance, and excels in inference workloads.
AMD says the MI300X is on par with the H100 in AI training performance, is competitive in price-performance, and excels in inference workloads.The power behind the MI300 is the ROCm 6.0 software stack. Updated software that provides support for various AI workloads. The new software stack supports the latest calculation formats such as FP16, Bf16 and FP8 (including Sparity). As a result of the optimizations, the speed increases are up to 2.6 times in vLLM, 1.4 times in HIP Graph, and 1.3 times in Flash Attention. ROCm 6 is expected to ship with MI300 AI accelerators later this month.

Contains 153 billion transistors
AMD Instinct MI300X is designed with CDNA 3 architecture. The chip, which has 5nm and 6nm sections, has 153 billion transistors. Starting from the design, the main interposer was placed with a passive membrane housing the interconnect layer using the 4th Generation Infinity Fabric solution. Interposer contains a total of 28 dice, including 8 HBM3 packs, 16 dummy dice between HBM packs, and 4 active dice, and each of these active dice takes 2 computational dice.
Based on the CDNA 3 GPU architecture, each compute die (GCD) has a total of 40 compute units corresponding to 2560 cores. There are 8 GCDs. So, there are 320 calculations and 20,480 core units in total. In terms of throughput, AMD will scale down a small portion of these cores and use a total of 304 compute units (38 CUs per GPU chip) for a total of 19,456 stream processors.

50% more memory
The MI300X also comes with a huge increase in memory space. It has 192GB of memory, which is 50% more than the previous accelerator MI250X. The new memories have 5.3 TB/s bandwidth and 896 GB/s Infinity Fabric bandwidth. For comparison, Nvidia H200 has 141 GB of memory and Intel Gaudi 3 has 144 GB of memory.
- Instinct MI300X – 192 GB HBM3
- Gaudi 3 – 144 GB HBM3
- H200 – 141GB HBM3e
- MI300A – 128GB HBM3
- MI250X – 128GB HBM2e
- H100 – 96GB HBM3
- Gaudi 2 – 96 GB HBM2e
In terms of power consumption, the MI300X has a consumption of 750 Watts, which is 50% more than the previous generation MI250X. It is 50 Watt higher than Nvidia H200.
In 2024, Nvidia will release Hopper H200 and Blackwell B100 GPUs, and Intel will release Guadi 3 and Falcon Shores GPUs. As competition in the field of artificial intelligence heats up, AMD is making efforts to break Nvidia’s dominance. It’s not hard to say that AMD’s new accelerators will also find a good place as companies sweep away every kind of AI solution available on the market.




 11500
11500



